

Previously
In a previous blog of mine, I talked about how to work with Bicep as an Infrastructure as Code language. In it, I briefly show the usage of the existing attribute within Bicep, but since it can be a topic on its own, let's dive a bit deeper into it and see how this can be used when you have to deploy your infrastructure more often and want to keep it up to date with the SKUs/Tiers your services are currently running on.
Existing in Bicep
When referencing an existing resource that isn't deployed in your current Bicep, you can declare it with the existing attribute. You can use the existing attribute when you're deploying a resource that needs to get values from an existing resource. This can be done by accessing the existing resource's properties through its symbolic name, for example:
resource StorageAccount 'Microsoft.Storage/storageAccounts@2019-06-01' existing = {
name: 'MyStorageAccountName'
}
output blobEndpoint string = StorageAccount.properties.primaryEndpoints.blobNOTE: The resource isn't redeployed when referenced with the existing attribute, it only is when looking it up within Azure itself.
The above example is used for the same scope, which means it will look for the existing resource within the same subscription, resource group, etc. But this can be adjusted to look at a different scope when you, for example, deploy similar services in their own resource group instead of a specific environment in one resource group. An example of a different scope would be:
resource StorageAccount 'Microsoft.Storage/storageAccounts@2019-06-01' existing = {
name: 'MyStorageAccountName'
scope: resourceGroup(MyOtherResourceGroup)
}
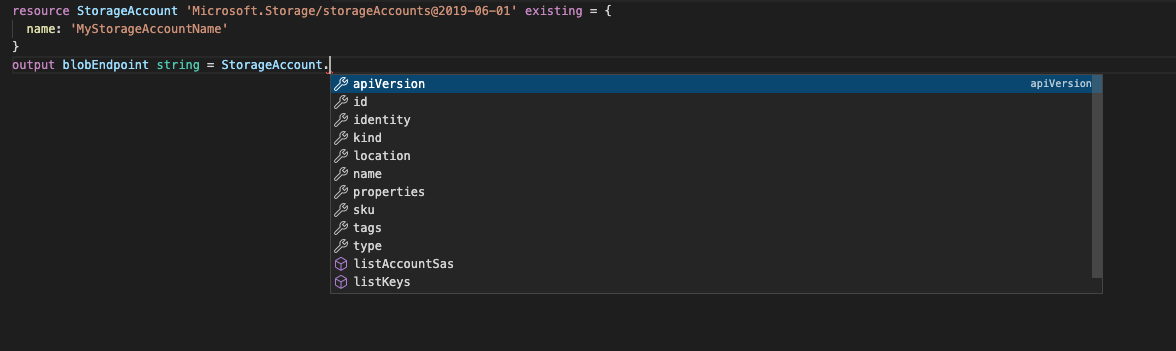
output blobEndpoint string = StorageAccount.properties.primaryEndpoints.blobAs stated before, you use the existing attribute to get specific values from an existing resource. In the examples we are looking at one of the Endpoints for Blobs, but this can be many things such as: apiVersion, id, identity, kind, location, name, properties, sku, tags and type.
Most of them have different sub-options, such as identity.principalId, sku.tier, properties.customDomain.name and many more. When using Visual Studio Code as your IDE, you will get both intellisense and auto-completion when writing your outputs, helping you to see all available options from the REST API.
Important to know is that If you attempt to reference a resource that doesn't exist, you get the NotFound error and your deployment fails. This is mildly inconvenient, but unfortunately there is no feature within Bicep to make the existing conditional and use an if-statement to determine what needs to happen.
This doesn't mean it is not possible, but this would require powershell/bash scripts to be used within Bicep.
Keeping you existing infra up to date
When you have your infrastructure up and running, especially with compute intense services, it is quite common that you eventually scale up your service to a higher sku/tier. While you might want to also adjust this in your Bicep, this is not always as easy as it might sound, especially in cases where a platform team is responsible for the deployment of your resources and/or if deployments are made modular, in which similar skus/tiers are used as a baseline across all different teams and individual adjusted services would then require exceptions, which are not always wanted or possible.
Since the resources are already available to us in this scenario, we can use the existing attribute to check our service and get the required values. In the example below, you can see this for an Azure SQL Database:
// sqlDbSKU.bicep
param DBName string
resource SqlDatabaseSKU 'Microsoft.Sql/servers/databases@2021-11-01-preview' existing = {
name: DBName
}
output SKUcapacity int = SqlDatabaseSKU.properties.currentSku.capacity
output SKUname string = SqlDatabaseSKU.properties.currentSku.name
output SKUtier string = SqlDatabaseSKU.properties.currentSku.tierAs you can see, we create 3 variables containing the needed values in our deployment, these variables can be used to make sure that when any redeployment needs to happen, for example, to add a new services or update an existing service, while keeping the skus/tiers of compute depending resource up to date. In the example below you will see how these variables are applied in a simple manner:
// main.bicep
param location string = resourceGroup().location
param ServerName string = 'sql-dataplatform-dev'
param DBName string = '${ServerName}/sqldb-dataplatform-dev'
module sqlDbSKU 'Modules/sqlDbSKU.bicep' = {
name: 'DBSKU'
params: {
DBName: DBName
}
}
module sqlDb 'Modules/sqlDb.bicep' = {
name: 'sqlDb'
params: {
location: location
DBName: DBName
SKUcapacity: sqlDbSKU.outputs.SKUcapacity
SKUname: sqlDbSKU.outputs.SKUname
SKUtier: sqlDbSKU.outputs.SKUtier
}
dependsOn: [
sqlDbSKU
]
}And the outputs are used within the sqlDB module as such:
// sqlDb.bicep
param location string
param DBName string
param SKUcapacity int
param SKUname string
param SKUtier string
resource SQLDatabase 'Microsoft.Sql/servers/databases@2021-11-01-preview' = {
name: DBName
location: location
sku: {
capacity: SKUcapacity
name: SKUname
tier: SKUtier
}
}While this might be for an Azure SQL Database, this will work for all kind of compute based services such as: Synaps SQL pools, App service Host plans, VMs and much more. The method remains the same, only a different service and some properties can be named differently.
What's next?
In previous blogs (here and here) we looked at how to extract all the different forms of access with Azure Logic Apps, but let's also look at how to apply them as well in the same manner.